Using Multiprocessing to Make Python Code Faster
Everyone could use more time, especially here at the Urban Institute, where researchers regularly analyze large datasets. Because we can’t create time, the research programming team focuses on making automated aspects of the research process faster. Many of our tools use Python, a programming language that makes it easy to analyze data through tools like pandas and NumPy but is often slower than compiled languages like C/C++ or Fortran. Nevertheless, several techniques can improve the speed of Python programs, often significantly. In this post, we discuss how Urban uses multiprocessing to speed up Python code.
Common research programming languages use only one processor
The “multi” in multiprocessing refers to the multiple cores in a computer’s central processing unit (CPU). Computers originally had only one CPU core or processor, which is the unit that makes all our mathematical calculations possible. Today, computers typically have anywhere from 2 to 128 cores, meaning that taking advantage of more than one can dramatically improve processing time.
Most programs and programming languages don’t take advantage of multiple cores. Programming languages Java and C automatically send tasks to multiple CPUs simultaneously, but Urban researchers mostly use Stata and SAS, with a growing number using R and Python. These “higher-level” languages come with out-of-the-box functionality and packages that make it easier to work with data, but these languages also default to using just one core, even in machines where multiple CPUs are available. By using just that single core, these programming languages are less efficient.
In Python, single-CPU use is caused by the global interpreter lock (GIL), which allows only one thread to carry the Python interpreter at any given time. The GIL was implemented to handle a memory management issue, but as a result, Python is limited to using a single processor.
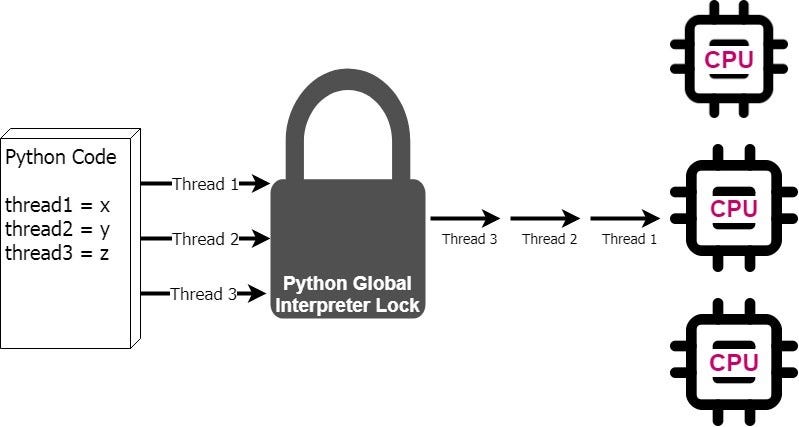
Multiprocessing can dramatically improve processing speed
Bypassing the GIL when executing Python code allows the code to run faster because we can now take advantage of multiprocessing. Python’s built-in multiprocessing module allows us to designate certain sections of code to bypass the GIL and send the code to multiple processors for simultaneous execution.
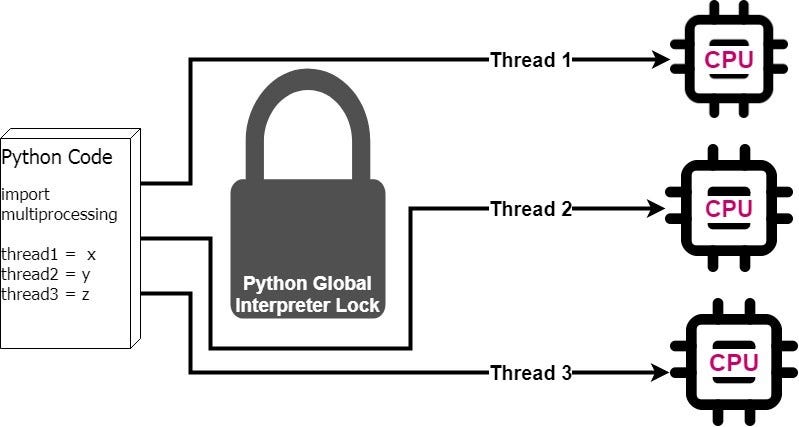
In this simplified example, assuming all three threads had identical runtimes, the multiprocessing solution would cut total execution time by a third. But this reduction isn’t exactly proportionate to the number of processors available because of the overhead involved in creating multiprocessing processes, but the gains represent a significant improvement over single-core operations.
Three requirements for multiprocessing
Before you can begin multiprocessing, you need to pick which sections of code to multiprocess. These sections of code must meet the following criteria:
1. Must not be reliant on previous outcomes
2. Does not need to be executed in a particular order
3. Does not return anything that would need to be accessed later in the code
For example, part of a cloud-computing system being developed with funding from the Alfred P. Sloan Foundation running Tax Policy Center microsimulation models has to perform several functions on each item of a sizable list. The section of code in question takes a large list of data and runs each data item through analysis and formatting. This code is independent of the rest of the program. It does not need to know the result of previously analyzed data to do its job, and the data it analyzes are not used in the rest of the code. If these sections required input from one another, the multiprocessing framework — in which the different sections are run in parallel — would break down. (There are ways around this, but that’s beyond the scope of this post.)
Here’s a simpler subsection of code that is a prime candidate for multiprocessing:
The traditional for-loop iteration goes through the list one by one and performs the functions on each item individually. In this model, the loops use only 30 to 40 percent of the available CPU power. If we were to use multiprocessing, the function would be executed on multiple list items at once and up to 100 percent of the CPU could be used on a multicore machine. Best of all, we would see a dramatic reduction in execution time.
How to use multiprocessing: The Process class and the Pool class
The multiprocessing Python module contains two classes capable of handling tasks. The Process class sends each task to a different processor, and the Pool class sends sets of tasks to different processors. We will show how to multiprocess the example code using both classes. Although both classes provide a similar speed increase, the Process class is more efficient in this case because there are not many processes to execute. Pool is most useful for large amounts of processes where each process can execute quickly, while Process is most useful for a small number of processes where each process would take a longer time to execute.
To use the Process class, place the functions and calculations that are done on each list item in its own function that will take a list item as one of its arguments. Next, import the multiprocessing module, create a new process for each list item, and trigger each process in one call. We keep track of these processes by making a list and adding each process to it. After creating all the processes, take the separate output of each CPU and join them into a single list.
To use the Pool class, we also have to create a separate function that takes a list item as an argument like we did when using Process. Then, using the multiprocessing module, create a Pool object called pool. This object has a function called map, which takes the function we want to multiprocess and the list as arguments and then iterates through the list for that function. After calling the function map, close the object to allow for a clean shutdown.
Unless you are running a machine with more than 10 processors, the Process code should run faster than the Pool code. Process sends code to a processor as soon as the process is started. Pool sends a code to each available processor and doesn’t send any more until a processor has finished computing the first section of code. Pool does this so that processes don’t have to compete for computing resources, but this makes it slower than Process in cases where each process is lengthy. For an example where Pool is faster than Process, remove the line time.sleep(2) in multiprocessing_func in both the Process and Pool codes.
The multiprocessed code doesn’t execute in the same order as serial execution. There’s no guarantee that the first process to be created will be the first to start or complete. As a result, multiprocessed code usually executes in a different order each time it is run, even if each result is always the same.
With multiprocessing, using higher-level programming languages doesn’t necessarily mean sacrificing speed. Certain aspects of the code can be run in parallel, which allows us to do our work faster and more efficiently. Thanks to multiprocessing, we cut down runtime of cloud-computing system code from more than 40 hours to as little as 6 hours. In another project, we cut down runtime from 500 hours to just 4 on a 128-core machine.
For more introductory information about multiprocessing in Python, check out this tutorial or this blog post.
-Ramani Gadde
