
How We Make Accessing Cloud Computing Power Simple
You might think the only organizations that take advantage of this age of “big data” are financial firms, technology firms, health organizations, and other groups that collect and use real-time information. But at the Urban Institute, our researchers analyze large datasets and run computationally intensive models. These data and models can sometimes run up against the limitations of our in-house servers, which is a problem for producing timely, policy-relevant research. Models that take days or weeks to complete hamper our ability to produce quick-turnaround, high-impact policy analysis.
Cloud computing platforms such as Amazon Web Services (AWS) Elastic Compute Cloud (EC2) provide easy access to powerful and cost-efficient computational resources. Renting a large, state-of-the-art computer or computing cluster in the cloud for a few hours is more cost-efficient than buying and maintaining a large server on-site.
People who have spun up their own EC2 instance from the AWS console or other cloud providers know that the process can be tedious and confusing. And even if researchers manage to make it through the spin-up process, they still need to figure out how to transfer and access the data, which typically sit on a personal computer or shared drive.
At Urban, we wanted to give researchers access to an EC2 environment for their computationally intensive data analysis projects without the hassle of getting them up to speed with storage, network access, authentication, installation, and the myriad options for instance sizes in AWS. To do so, we built our own in-house solution for Windows and Linux operating systems, and our researchers have seen significant gains.
Speed increases are significant
Before we talk about how the system works, let’s talk about the benefits of cloud computing and when it should be used. The on-demand cloud computing environment is most useful for projects that have datasets too large to read into memory on a standard desktop (i.e., they cause your computer to freeze) and for long-running independent jobs that can be parallelized (simultaneously run in pieces across a computer’s cores).
One team at Urban had a project that involved a 50-gigabyte dataset that included text from more than 65 million Twitter observations. Using an x1.16xlarge instance, we could load hundreds of gigabytes of data into R and then parallelize the analysis across all 64 virtual cores. A job that was initially estimated to take 30 hours, but would often freeze even our most powerful on-site machines, ultimately ran in less than 30 minutes in the cloud. A cluster analysis project, which originally took 500 hours to run on a single thread on our on-site servers, took just 4 hours when parallelized using the 128 virtual core x1.32xlarge instances on AWS.
Accessing the instances
We created a simple web submission form using R Shiny, a package that makes it easy to create a web application within R. Researchers see a web form with a few inputs, text explaining their options, and a tool for estimating which instance size they need. Researchers simply need to understand the size of the dataset, and our form recommends the size of the instance to select.

From there, users need only to choose which operating system they want to use and the size of the computer (EC2 instance) they need. We use the web form to subset the numerous combinations of instance type and size down to a list of six that are most suitable for our research needs, providing researchers only the newest, fastest compute instances.
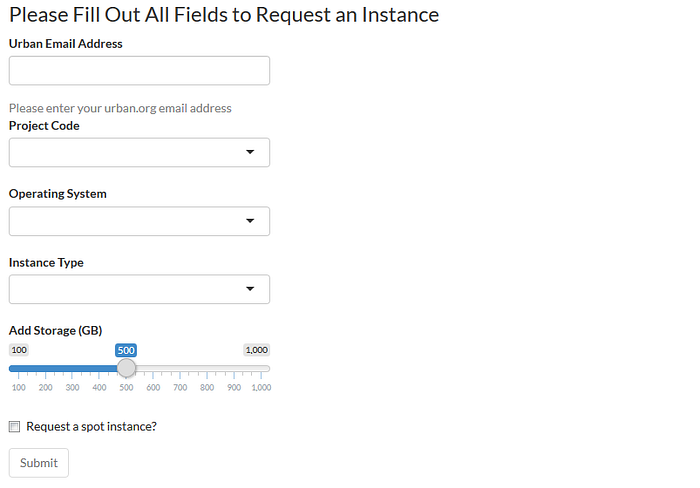
All the other AWS details that are typically confusing to first-time cloud users — such as the image, subnet, IAM (identity and access management) role, and security group — are abstracted away from researchers and programmatically handled on the back end. When they have made their choices, they click Submit to request their instance.
How it works
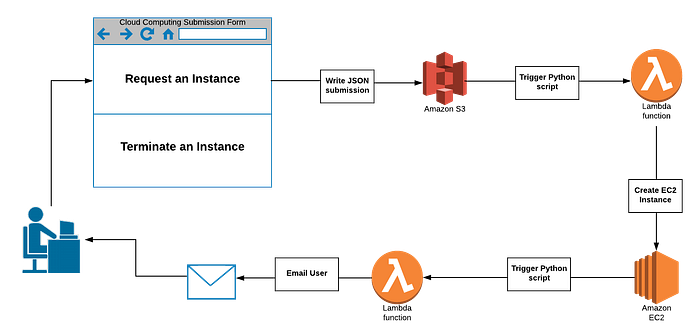
When the instance request form is submitted, the details are saved as a JSON file to a bucket in Simple Storage Service (S3), an AWS service that allows you to save data remotely in the cloud. Saving a file to S3 triggers a Python script in AWS Lambda (a serverless computing platform) that uses boto3 (a Python package that allows developers to access AWS services programmatically) to read in the submission parameters and spin up the properly sized and formatted instance. We use Lambda because it allows us to run functions without having to maintain a server; we pay only for the brief time the boto3 script runs to spin up the instance.
Once the instance is ready for use, a second Lambda function (again powered by boto3 and written in Python) is triggered that sends an email notification to the researcher with instructions on how to access the instance.

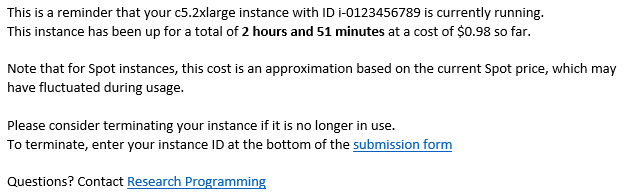
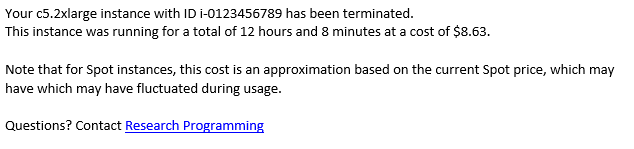
A researcher sees none of this back-end infrastructure and instead simply receives this email 30 seconds after submission for Windows users or 3 to 5 minutes after submission for Linux users. A researcher simply needs to follow the emailed instructions to access the instance. Emails are sent every few hours while the instance is running to show researchers the current total cost of use and a reminder to terminate the instance once they are finished to reduce costs. These reminders are powered by time-triggered Lambda functions.
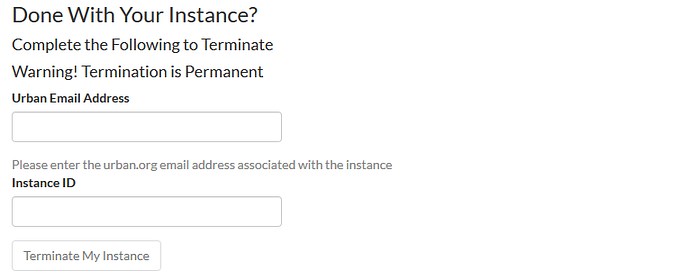
When researchers are done with their work, the same submission form is used to terminate the instance. Entering the necessary information and clicking “Terminate My Instance” writes a second file to S3 and triggers another Lambda function that uses boto3 to properly shut the machine down. A final confirmation email is sent with the total cost of use.
How the instance works: Windows
A Windows instance is set up with a custom Amazon Machine Image that includes access to R and RStudio, Python, and Stata for data analysis; the Microsoft Office suite; and git and GitHub Desktop for version control. For our R installation, we use the Microsoft Open R distribution. This version of R comes precompiled with the Intel Math Kernel library, which increases the speed of matrix algebra operations and many modeling tasks.
Windows instances are accessed using Windows Remote Desktop Connection. Thanks to AWS Directory Service, users can log in using the same credentials they use for their personal work computers.
For data storage, we employ AWS Storage Gateway. This allows Urban Institute researchers to easily move their files to the cloud without having to know anything about S3. The file share is mapped as a network drive on the user’s local machine and on the EC2 instance. Users simply copy their data into the mapped drive, and they are immediately available for use within any EC2 instance. All data processing can be completed on the shared drive, where the data are stored even when the instance is shut down and can be downloaded locally whenever necessary.
For Windows instances, we initially had issues with start-up times for applications on their initial launch. Simply opening programs, such as RStudio and Spyder, would take a couple of minutes to load. To overcome this bottleneck, we decided to employ a queue of Windows instances that have had their root device volumes “prewarmed” with the dd program. This queue is stopped, resized, and started as requested, which cuts down on instance initialization time. As a result, our whole process, from form submission to the email indicating the instance is ready, typically takes less than 30 seconds.
How the instance works: Linux
The configuration of Linux instances is primarily handled with a bash script that is run on instance launch. We start with an Ubuntu image and install the Docker program.
To give users access to RStudio Server, we run a tidyverse container courtesy of the Rocker Project. This speeds up the configuration process and installation time, as Rocker already handles the installation of R and RStudio and the compilation of the tidyverse packages. With daily builds of the Rocker images, Urban researchers have seamless access to the latest versions of all software and packages with no effort on our part. Similarly, the scipy-notebook image from Project Jupyter allows us to easily give users access to a Jupyter Notebook server running Anaconda3 with the full stack of popular scientific libraries installed for Python.
This process is fully elastic and does not depend on a queue of prelaunched instances, unlike the Windows process, but because it uses Linux, users are typically more advanced data science practitioners. Researchers must be familiar with S3, and start-up times for the instance range from 3 to 5 minutes, on average.
More accessible tools for the big data age
As Urban researchers use larger datasets and more computationally intensive modeling techniques, our data science team needs to deliver easy-to-use, secure, and powerful services. Translating new technical capabilities, such as scalable cloud computing services, to a broader research audience will ensure that Urban can conduct new, more timely research and leverage emerging big and unstructured data sources to inform policy in real time.
