
Automating Data Quality Checks with Great Expectations
Data management and quality assurance is key to delivering rigorous and reliable policy analysis. The Urban Institute’s Housing Finance Policy Center uses multiple property records data sources, including Agency Mortgage-Backed Security data and Home Mortgage Disclosure Act data, to study structural barriers homeowners of color face. Our data science team aims to support the Housing Finance Policy team, and all Urban researchers, in building a robust data quality assurance system, which makes quality checks automated, iterative, and fast.
Before statistical analysis or building machine learning models, cleaning data can take up a lot of time in the project cycle. Without automated and systematic data quality checks, we may spend most of our time cleaning data and hand-coding one-off quality checks. As most data scientists know, this process can be both tedious and error prone.
Having an automated quality check system is critical to project efficiency and data integrity. Such systems help us understand data quality expectations before beginning the project, know what to expect in our data analysis, and make communicating the data’s intricacies much easier. For example, a good metadata system in which the researchers define the variables included in the data, the variable values (e.g., “1” indicates male and “2” indicates female), and even the data types (e.g., string or integer), sets rules for how data should look, helps quickly find errors, and facilitates researcher collaboration. Further, regularly updated data, such as most published datasets Urban uses, benefit from automated refreshes and automated data monitors, reducing the need for continuous human intervention.
To help our colleagues in the Housing Finance Policy Center, we developed a comprehensive data quality system. The system consists of four parts: a data pipeline infrastructure, a metadata system, an open-source data quality tool called Great Expectations, and a front-end web page that lists all the datasets available to researchers, along with their quality check history and reports. To connect all the parts, we created an automated process that connects code updates, data file generation, quality checks, and shares notifications of the results. This allows researchers to conduct data checks without having to interact with complex data infrastructure. First, a researcher can write up code for generating data files and push the code to Github. Once the code updates are approved, it gets pulled into a local server and executes. Data files are then generated and sent to an S3 (Amazon Web Services’ data storage service) bucket. This triggers a quality check pipeline that automatically runs on the cloud. Once the check finishes, the reports are stored in S3 and displayed on the website, where researchers can easily find, view, and share the reports.
Great Expectations is a key part of the quality check system. It offers automated unit tests for datasets (also known as pipeline testing) to help guard against upstream data changes and monitor data quality. At a high level, it conducts checks on a researcher’s dataset against the data quality “expectations,” the parameters researchers provide to the system. This system has the following main advantages:
- Compatibility with tools and systems we already use. Great Expectations is a Python-based application, which is applicable to various data forms, including in-memory Pandas or Spark data frames, data files stored in S3, or Relational Database Service such as MySQL and PostgreSQL. It also allows you to invoke checks in the command line without using Python.
- Comprehensive unit tests. Great Expectations offers a variety of expectations researchers can configure. The tool defines expectations as statements describing verifiable properties of a dataset. Some commonly used expectations include the following:
· verifying column names and row counts
· identifying missing cells
· checks on data types
· checks on expected values
· reporting statistical characteristics (mean, median, and minimum and maximum values) of certain columns
These expectations work as functions in Python. For example, to check if a column named “student_id” exists in a dataset, we simply read data into memory in Python, initialize a Great Expectations session, and call the following function: expect_column_to_exist(“student_id”).
Not only does it offer more than 50 built-in expectations (full list here), it also allows data engineers and researchers to write custom expectation functions. For our project, we wrote a custom function to check all positive unique values for certain columns in a dataset.
- Easy to use without complex coding:
Great Expectations applies tests directly on data. Some coding is needed at the beginning to fit Great Expectations into a data pipeline (such as writing custom expectations). But once the system is set up, checks can be automatically conducted whenever the new data comes in.
- Results delivery with HTML reports and Slack notifications:
Great Expectations generates an HTML report that compiles the quality check outcomes for a dataset. It can be configured to display very detailed information, such as the unexpected values for a column, that can simplify debugging. The HTML reports are neat, organized, and easy to understand.

If a researcher is looking to get a quick answer on how many checks passed or failed, Great Expectations can be plugged into a Slack channel and will post messages that summarize check results.
- The profiling functionality automates generating summary statistics:
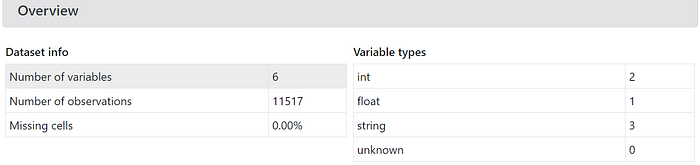
When new datasets come in, researchers may want a quick sense of how the data look. Instead of trying to set up everything in Pandas to describe the dataset, automatic profiling creates a summary statistics report, which provides a comprehensive overview, including the number of variables, observations, missing cells, and data types. It then provides a summary of value counts and distribution for each column. Below are two examples of how profiling presents this overview and descriptive summary.

Implementing Great Expectations is fairly simple. Three main elements are needed to conduct the check.
Expectation suite: This consists of a collection of expectations in JSON format, which helps keep the expectations organized and reusable. An example expectation suite looks like this:
{
"data_asset_type": "hmda",
"expectation_suite_name": "hmda_1998_processed_suite",
"expectations": [
{
"expectation_type": "expect_column_to_exist",
"kwargs": {
"column": "my_var_1"
}
},
{
"expectation_type": "expect_column_values_to_be_of_type",
"kwargs": {
"column": "my_var_2",
"type_": "str"
}
}
]
}1. Data: Our data are stored in S3. Once the data get updated in S3, the quality check pipeline will be triggered.
Data context: This serves as a central place to document all resources and configurations for the quality check, including expectation suites, data sources, and notification settings. The data context is configured via the .yml file named great_expectation.yml. In our case, we also automated the .yml file to update through its metadata. The data source section of the .yml file looks like this:
datasources:
embs_fhl_aggrhist:
batch_kwargs_generators:
summary_statistics:
assets:
embs_fhl_aggrhist:
path: /dev/data/embs_fhl_aggrhist.csv
class_name: ManualBatchKwargsGenerator
class_name: PandasDatasource
data_asset_type:
class_name: CustomPandasDataset
module_name: custom_module.custom_dataset
module_name: great_expectations.datasource
embs_fhl_cpnhist:
batch_kwargs_generators:
summary_statistics:
assets:
embs_fhl_cpnhist:
path: /dev/data/embs_fhl_cpnhist.csv
class_name: ManualBatchKwargsGenerator
class_name: PandasDatasource
data_asset_type:
class_name: CustomPandasDataset
module_name: custom_module.custom_dataset
module_name: great_expectations.datasourceThe automated quality check system ensures the data we have are what we expect and are ready for downstream policy analysis. We are currently working to make the system easily applicable to other datasets available at Urban so more data users and Urban’s policy work can benefit from this system.
