
Analyzing the Privacy and Utility Trade-off for Synthetic Datasets with Imbalanced Demographic Groups
In recent years, synthetic data — or statistically representative pseudo records usually based on statistical models — have gained popularity as a way to increase data privacy while preserving the utility of a dataset. Many people responsible for protecting and disseminating data believe synthetic data can be the primary mechanism to protect confidentiality while releasing some data to the public. In fact, the United States Census Bureau is researching how to incorporate synthetic data into their data privacy workflows.
Although the method has existed for more than five decades, little research has examined the effects of synthetic data on the utility of imbalanced data — data with clear majority and minority subgroups. Smaller demographic groups — along dimensions of race, ethnicity, gender, sexual orientation, location, and other characteristics — face unique challenges in the protection and use of their data, including undercounting and misrepresentation that can lead to adverse effects, especially during times of crisis like the COVID-19 pandemic.
Having fewer observations compared with a large demographic group makes the these smaller subgroups more vulnerable to exposure, requiring further privacy protections for that smaller group. People of color, for instance, have expressed heightened distrust in institutions’ ability to safeguard their data and increased concern over their physical privacy. But methods for increasing privacy protections often reduce information’s utility. Utility in this sense refers to how accurately public data represents the actual data. This disproportionate application of privacy protections to smaller subgroups can have drastic outcomes when the data are used for important decisionmaking, such as the allocation of social service funding.

Recently, we tested how various synthetic data techniques could affect the utility and privacy trade-off for smaller identity groups. To create synthetic data, many organizations — including the Urban Institute — use sequential synthesis, which involves synthesizing a dataset one variable at a time. Because each new variable relies on previously synthesized variables, the order the variables are synthesized in greatly affects the data’s utility. If a variable is initially synthesized poorly, those errors can cascade into variables synthesized later. Our tests — the results of which we present in this post — sought to understand how the variable order used during sequential synthesis affected the utility of small identity groups’ data compared with the utility of the majority group’s data.
Methodology
We generated simulated datasets with 10,000 observations and varying percentages of demographic group representation (1 percent, 5 percent, and 10 percent) to investigate potential utility disparities that arise when generating synthetic data using imbalanced data. We added the following numeric variables to the simulated data by sampling from normal distributions with constant variance:
· one dependent variable based on the imbalanced variable
· one variable independent of the imbalanced variable
· two additional variables perfectly correlated (r² = 1) with the above variables
We analyzed mean utility using the first two variables and correlation utility using correlated pairs. Mean utility gauged how well the synthetic data captured variable averages, and correlation utility measured how well it preserved variable correlations. Maintaining high mean and correlation utility is crucial for accurate results when using synthetic data to generate summary statistics or building predictive models. We used the absolute proportion difference between the actual and synthetic values as a proxy for utility. Higher values were associated with worse utility.

To validate the results found with the simulated data, we used a 10,000-unit random sample of the 2022 American Community Survey’s (ACS) Public Use Microdata Sample for North Carolina. We identified the imbalanced variable as American Indian and Alaska Native (AIAN) status. Only 3.5 percent of individuals in the randomly sampled dataset identified as such. We selected variables comparable with the simulated data for the ACS data (table 1). Weeks worked in the past year and hours worked per week were uncorrelated with AIAN status and correlated with each other (r² = 0.9). In contrast, family income and income-to-poverty ratio were correlated with AIAN status and each other (r² = 0.55).

We generated multiple iterations of synthetic data from all possible orderings of the variables to assess the effect of variable order. We hypothesized that not prioritizing the variables most correlated with the AIAN group would lead to worse utility for that group than the majority at a 5 percent significance level. A more detailed breakdown of the methodology for this project can be found on GitHub.
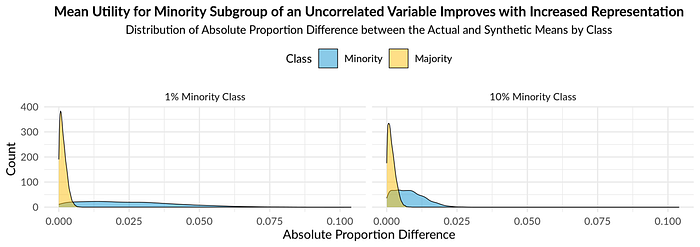
1. Mean utility for the smaller subset of an uncorrelated variable is consistently worse
Our analysis found that mean utility for the variables uncorrelated with AIAN status was significantly worse for AIAN members in the simulated and ACS data. This disparity was consistent across all variable orders and could result in cascading effects that affect decisions regarding social welfare distribution and labor market analyses.
Our analysis of the simulated data found that utility improved as the representation of the smaller group increased (figure 2). Therefore, balancing out the classes in the confidential data before synthesis could help reduce disparities. For example, data stewards could weight small demographic group observations in the statistical models or oversample from those groups.
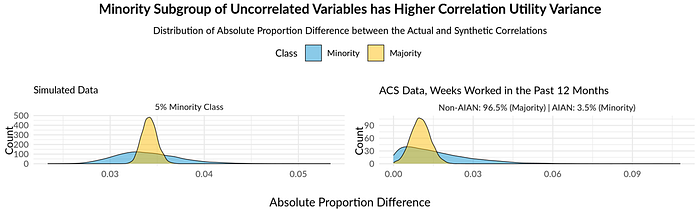
2. The correlation utility for the smaller group has a higher variance
Our analysis found similar correlation utility for the AIAN group and majority group on average. However, the correlation utility for the AIAN group had higher variance (figure 3). Higher variance could hinder predictions for this group or identifying variables associated with different subgroups. Healthcare, for instance, has an increasingly data-informed landscape and any breakdown correlation utility during synthesis could lead to inaccurate evaluation of these groups.
3. Variable order gives mixed results across simulated and ACS data
With the simulated data, the AIAN subgroup demonstrated the best mean utility when the imbalanced variable was synthesized first and the correlated variable was synthesized last. In contrast, the correlation utility improved when the imbalanced variable was synthesized last and the correlated variable was synthesized first (figure 4). These results suggest there may be a trade-off between maintaining mean utility and correlation utility for a variable linked to an imbalanced one. Data stewards must carefully consider which metric to prioritize based on their specific needs when synthesizing data.
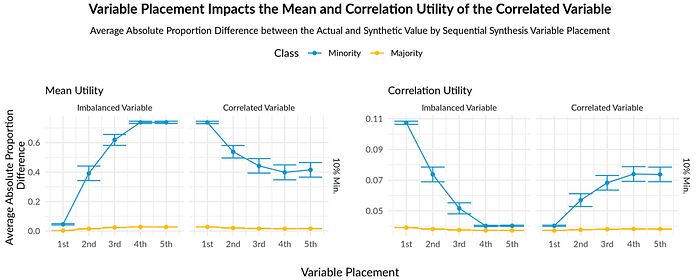
These findings did not hold up in the ACS data. Unlike the simulated data, the ACS data do not have constant variance, which likely affected the results. We hypothesize that differences in variance between the demographic groups in the data would also affect utility, as variables with higher variances pose challenges for statistical models to predict accurately. Future research could explore adjusting the variance of the simulated data to more closely resemble real-world data, providing a better proxy for obtaining more accurate estimates.
Addressing utility disparities in imbalanced synthetic data
As synthetic data generation becomes more widely used, the differences in synthetic data quality between various groups could perpetuate or even worsen inequities in data-informed decisionmaking. Special attention should be paid to detecting these differences to ensure equitable data utility across all groups.
Based on our research, we propose the following steps to proactively address utility disparities in imbalanced synthetic data:
1. Prioritize accurate and balanced representations of small demographic groups in the confidential data if possible or consider using a method (e.g., weighting) to balance the data before synthesis.
2. Consider how the placement of the imbalanced and correlated variables in the sequence best preserves the mean and correlation utility of variables linked to an imbalanced category.
3. Disaggregate utility measures by subgroup to catch potential disparities.
4. Collaborate with affected communities to understand the real-world effects of data misrepresentations. This understanding can inform strategies regarding which variables are most important to preserve.
